

New Blog, Hello Gatsby!
September 28, 2023Hello blog! The last entry I wrote in this blog was just before the COVID-19 pandemic hit us all. Whew, it seems like it was ages ago. A lot…
Written by Edin Kapić Insatiably curious code-writing tinkerer. Geek father. Aviation enthusiast. Cuisine journeyman. Follow me on Twitter
Hello blog! The last entry I wrote in this blog was just before the COVID-19 pandemic hit us all. Whew, it seems like it was ages ago. A lot…
Another day, another small learning. SITUATION I have been extending ASP.NET Core REST API service that returns redirect (HTTP 301) results…
I have been chasing a weird bug in a solution I've been working on. The insight on how certain C# feature work by design, which I got after…
Last Saturday I attended the NetCoreConf Barcelona, a free conference dedicated to .NET Core and related technologies. I spoke about the key…
Desde hace unos años observo una tendencia en los eventos técnicos a los que asisto o los que colaboro a organizar. Esta tendencia es la…
I've been doing a lot of SPFx, NET Core and Office 365 related development and I have several stories to share. During the implementation of…
It has been more than a year that I have written on this site. I could bring all kind of excuses. The newly found paternity has taken a toll…
A very annoying bug appeared few weeks ago in one of our production environments with SharePoint 2013. SYMPTOMS You have a custom list with…
Tenía la intención de escribir un post resumen del año 2016, pero los posts de los compañeros como Marc Rubiño o Yeray han tenido que ver en…
En esta serie de posts intentaré hacer un resumen de las posibles opciones que tiene un desarrollador (o desarrolladora) para programar una…
Después de "liarla" un poco parda este verano con las opiniones incómodas sobre la diversidad en la comunidad técnica y el "círculo interno"…
Después de organizar el primer SharePoint Saturday Barcelona el año pasado, y colaborar en la organización del SharePoint Saturday Madrid es…
Few days ago I used NDepend tool to analyze the code of one of our bigger projects in Sogeti. Here are my thoughts on the tool. NDepend is a…
After an overwhelming response to my last week post about the lack of diversity and inclusion in the technical communities, I wanted to…
For a long time now, I’ve been wishing to write about the gender and diversity gap in the technical community. Today felt like that day, so…
Mucha gente me ha preguntado como consigo estar al día de las novedades tecnológicas del mundillo SharePoint/NET/Web/JS sin morir en el…
Few weeks ago I had a nasty bug on customer premises where a combination of SharePoint 2013 and ASP.NET UpdatePanel control resulted in some…
Los que me conocen saben que soy un poco Grammar Nazi. Lo reconozco, me gusta corregir la ortografía o la pronunciación en inglés cuando se…
Last week I was in Germany, in the little village of Erding (near Munich), delivering two sessions at SharePoint Konferenz 2016. It was a…
La semana pasada estuve participando en la mayor conferencia de .NET que se hace en España: la DotNetSpain Conference 2016. Este año se…
We all know IDisposable interface in NET Framework. It is used to signal to any object with dependencies to other objects when should it…
In the last couple of weeks I've been reading two books that I hoped would help me with my role as a practice lead. One of them is "Debuggi…
Last week I was in Stockholm for the annual European SharePoint Conference 2015. A little bit tired after being in USA for MVP Summit the…
In the first half of this year I've been busy producing a new course for Pluralsight, called "Building Highly Scalable Web Applications in…
Como ya muchos sabéis, SharePoint 2016 IT Preview está disponible para descarga desde ayer, 24 de agosto de 2015. Con ello, han empezado a…
Yesterday (July 11th) I was presenting at the very first SharePoint Saturday London. The SPS event was very well organized by Peter Baddeley…
El día 9 y 10 de junio se celebró la conferencia CEUS by Iberian SharePoint Conference 2015, en las oficinas de Microsoft en La Finca…
En el First Monday de mayo los miembros de SUG.CAT nos reunimos para hablar de las herramientas de desarrollo en nuestros proyectos de…
I have been unusually silent on Twitter and on this blog in the last few weeks. The reason is that I have left Spenta / Beezy, after two…
I have been thinking lately of the evolution I witnessed in the corporate intranets working on many SharePoint projects. In this post I'm…
En los últimos meses desde SUG.CAT estamos inmersos en la organización del primer evento en el formato de SharePoint Saturday. Desde hace…
As it happens with the last Fool's Days, I got the email from Microsoft that congratulate me on being (re)awarded the Most Valuable…
Yesterday Microsoft announced the availability of Azure App Services, a new high-level grouping of services for building apps on Azure cloud…
Este sábado 21 de marzo de 2015 hicimos el primer evento trimestral del año desde nuestro grupo de usuarios de SharePoint de Catalunya SUG…
My last adventure with Lightswitch was trying to detect when a popup window inside a screen is closed. You can close a Lightswitch popup…
Another weird SharePoint app bug happened yesterday. The solution was fairly easy once you know what's going on, but it's just weird…
Last Friday, March 13th, I had the opportunity to speak about personal branding for developers at the Microsoft MVP Open Day for Spain…
Another one of my strange adventures with Lightswitch has made me look deep inside the navigation framework that Lightswitch uses. I will…
I found an odd problem this week in a SharePoint-enabled Lightswitch HTML Client application. I am sharing the solution here in case there…
As I mentioned in my previous post, last weekend was well spent with the SharePoint Saturday crowd in Stockholm, Sweden. In this post I want…
Last weekend I have attended another SharePoint Saturday, this time in Stockholm. The weather was nicer than the last year, and the…
Well, it has been doubted lately but Microsoft has finally spilled the beans on the next on-premise version of SharePoint. Office General…
En la última entrega de esta serie de posts sobre el modelo de apps en detalle, hablé de las aplicaciones Low-Trust y aplicaciones High…
I have been busy for the last few days migrating my blogs to a new platform, as you can see. In this post I will summarize what I have…
I would like to do a short retrospective look to the rapidly-changing landscape of SharePoint in the last few years, followed by a personal…
En estos últimos días hay un debate calentito sobre el futuro del modelo de apps de SharePoint. El día 22 de diciembre el gran gurú…
In the last months I have been busy working on a project that includes high-trust on-premises SharePoint 2013 app that is accessed by many…
Welcome to the third installment of the business value of social computing post series. You can review the first and the second post of the…
En los primeros dos posts de esta serie hemos visto la evolución del código personalizado en SharePoint y la arquitectura básica del modelo…
En el primer post de esta serie sobre el modelo de apps de SharePoint 2013, expliqué la problemática de tener código a medida en SharePoint…
Hola a todos, En un reciente proyecto me he visto involucrado en mucho detalle en el modelo de apps de SharePoint 2013 en entornos…
In a recent project I have been writing code to check if an arbitrary user can create new documents in certain document libraries. In order…
A strange situation happened to me few days ago, when checking a portion of SharePoint 2013 server-side code on a custom form. Basically, it…
Note: This is a second post in the series. You can check the first post to refresh the concepts. In the first post I have defined what…
The European SharePoint Conference is less than three weeks away and I’m delighted to be part of such an exceptional line up. The conference…
On the April Fools Day, I have received the confirmation that my MVP Award has been renewed. I wish to thank to everyone who made it…
Hello there! I'd like to start a new serie of posts where I want to hightlight and demystify the benefits of introducing and extending…
Hace dos semanas estuve en "La" conferencia de SharePoint en Las Vegas, Estados Unidos. Fueron cuatro días intensos en los que empaparse de…
Tomorrow I will be flying to Las Vegas, for my third SharePoint Conference there (you can see my impressions from 2009 and 2012). This time,…
A puzzling SharePoint search alert behaviour was keeping our team of three scratching our heads for days. If you speak Spanish, you can…
A very weird and hard to pinpoint SharePoint error has haunted me these last days. The Symptoms You have a SharePoint site collection that…
Ayer lunes 13 de enero de 2014 nos reunimos para la Asamblea general ordinaria de la asociación SUG.CAT en Barcelona. Todavía no tenemos el…
In case you missed it, the European SharePoint Conference 2014 programme is now available and I’m delighted to announce that I am speaking…
Last month I attended SharePoint Summit 2013 in Vancouver as a speaker. I was really looking forward to it, being my first time in Canada. F…
Another interesting issue arose the last week. I was tasked with implementing a BCS .NET connector to a OTRS web issue tracking service, as…
Estamos agotando las entradas de la Iberian SharePoint Conference a un ritmo vertiginoso. Las entradas para la conferencia y para los…
If you have custom JavaScript file loaded in your master page, as we usually do in SharePoint, you might have stumbled upon the problems…
I just had a strange error the other day, deploying Business Connectivity Services (BCS) model arranged around a NET assembly. When…
__Ayer estuve inspirado para escribir la primera parte de esta guía, pero no quería extender el post y atiborrarlo de contenido. Prefiero…
La Iberian SharePoint Conference está en plena marcha. Ya hemos abierto el proceso de registro para que podáis comprar vuestras entradas…
As you probably know from my previous posts, I have been configuring a wide-scale document management solution using Content Organizer…
Desde la organización de la Iberian SharePoint Conference 2013 la semana pasada cerramos el preregistro con 250 personas apuntadas. A estas…
In this post I'll highlight my recent "battle" with SPSiteDataQuery and Managed Metadata used for cross-site navigation, with the hope that…
Continuando con la serie de posts sobre como programar bien en JavaScript, en este post vamos a ver el tema de encapsulamiento. Como sabéis,…
La semana pasada estuve en TechEd Europe en el recinto firal de IFEMA en Madrid. Iba como staff voluntario para ayudar con los Hands-on Labs…
In one of the current projects I have to connect to OTRS ticketing back-end. OTRS is an open-source ticketing application and has a web…
Tal como dije en mi post del año pasado, una de las cosas que íbamos a aprender los desarrolladores de SharePoint con la nueva versión es…
Supongo que la mayoría de los lectores del blog ya saben de que va el asunto, pero desde hace tiempo quería hacer un post sobre ello. Pues…
It took me much more time to finish The Art of Community (2nd Edition): Building the New Age of Participation than usual, due to my recent…
In this occasion I have been exploring the possibility of an auto-organizing document hierarchy in SharePoint 2010, made with Content…
This is the subject of the email I received on the Fool’s Day. Luckily it was not a joke, it was the confirmation of my nomination as…
Este es el asunto del correo electrónico que recibí el día 1 de abril, el día de los inocentes en el resto del mundo. No, no era una…
A few months ago I was confirmed as a speaker on the SharePoint Evolutions Conference (aka SPEVO13) that will take place in London, from Apr…

Thanks to the good people at O’Reilly User Group Program (Josette, you rock!), the SharePoint User Group I lead has access to review copies…
En la serie de posts sobre el desarrollo de apps de SharePoint 2013, hemos visto hasta ahora un ejemplo de app de SharePoint 2013 para niños…
En la serie de posts sobre el desarrollo de apps de SharePoint 2013, hasta ahora hemos visto como se desarrolla una app sencilla y alojada…
Hoy hemos celebrado el evento largamente preparado y esperado, sobre las novedades de SharePoint 2013. Gracias a la colaboración de AvePoint…
Después de tantas semanas intentando cerrar un evento con un poco de consistencia para la comunidad de SharePoint en Catalunya, ya tenemos…
Hoy se ha acabado la SharePoint Conference 2012. Ha sido un día más corto, con sólo tres sesiones. Hoy también he tenido el honor de hablar…
El tercer día de la SharePoint Conference en Las Vegas ha sido bastante ajetreado, para mí. He podido participar en el feedback que recoge…
El segundo día de la SharePoint Conference empezó igual que el primero, con mucho contenido y poco tiempo para decidir a qué sesión asistir.…
Hoy ha sido el primer día de la conferencia de SharePoint en Las Vegas. Había mucha expectación por la keynote inicial, a ver que iba a…
Ayer celebramos la reunión mensual de la asociación SUG.CAT, en el lounge-bar 7Sins. A pesar de los imprevistos y la logística, pudimos…
Desde SUG.CAT, la asociación de usuarios de SharePoint en Catalunya, estamos encantados de invitar a todos los interesados a nuestro encuent…
Ya falta menos para la conferencia SharePointera más grande del mundo. Si, estoy hablando de la Microsoft SharePoint Conference 2012 (o SPC…
Ayer por la tarde saltó la liebre: la versión RTM de SharePoint 2013 y Office 2013 estaba liberada en MSDN y TechNet. Tardé nada y menos en…
I decided to give a try to a new tool that has been published at CodePlex, called SharePoint Solution Deployer (SPSD). It is built to…
I installed Windows 8 on my Dell Studio laptop two weeks ago, and I found out that the Synaptics TouchPad driver supplied by Dell does not…
Despúes de ver la introducción al modelo de las aplicaciones de SharePoint 2013 y de repasar los conceptos básicos de la infraestructura, va…
I was trying to activate my company’s Windows 8 Enterprise license but I was met repeatedly with the “No DNS Servers Configured: Code…
El viernes pasado, 5 de octubre de 2012, tuve el placer de asistir como ponente en el encuentro del grupo de usuarios de .NET en Andorra, An…
Después de la introducción del post anterior, vamos a ver la arquitectura física de una App de SharePoint 2013. Para ello, no hay nada mejor…
A quick mystery solved on a customer intranet today. The Symptoms You tag some PDF files, alongside other content in SharePoint 2010. Then…
En esta serie de posts iré explicando en detalle el nuevo modelo de Apps introducido en SharePoint 2013 Preview. La idea que tengo es…
Aquí os dejo el ejemplo completo de mi artículo “SharePoint por KO: KnockoutJS” de la revista CompartiMOSS #13. ACTUALIZACIÓN 21/09/2012: He…
El controlador de dominio El servidor de SharePoint: Windows Server El servidor de SharePoint: SQL Server El servidor de SharePoint…
Since I wrote my last blog post in April, I have been busy updating my other, Spanish-speaking blog, together with learning a lot about…
El controlador de dominio El servidor de SharePoint: Windows Server El servidor de SharePoint: SQL Server El servidor de SharePoint…
El controlador de dominio El servidor de SharePoint: Windows Server El servidor de SharePoint: SQL Server El servidor de SharePoint…
El controlador de dominio El servidor de SharePoint: Windows Server El servidor de SharePoint: SQL Server El servidor de SharePoint…
El controlador de dominio El servidor de SharePoint: Windows Server El servidor de SharePoint: SQL Server El servidor de SharePoint…
Ayer pasé una buena tarde, participando en las microcharlas de la comunidad CatDotNet, en el Cafè Pagès de Gràcia en Barcelona. Me…
Como no vivo debajo de una roca, desde el lunes pasado vivo digiriendo bastante información sobre SharePoint 2013 Preview. A veces me siento…
Hace unas semanas estuve de vacaciones en la maravillosa isla de Cuba. Además de disfrutar de la riqueza cultural y paisajística del país…
I had a very exciting SharePoint Saturday in Brussels, Belgium this Saturday 28th. I met many SharePoint experts and fellow speakers and I…
In the past few weeks we’ve learned that Microsoft has changed the structure of the certification program that has been established in 2007.…
No sé si fiarme mucho, pero en la web de un desarrollador turco llamado Timur Sahin ha salido un pantallazo que el dice que es de la beta…
Today was a day packed with investigation and troubleshooting weird JavaScript errors on a customer premise. I put this information on my…
Los días 4 y 5 de abril de 2012 estuve en la conferencia regional de Microsoft Bosnia-Herzegovina, llamada MS NetWork 2.0 en la preciosa (av…
Here are the slides from my session at MS NetWork 2.0 conference in Mostar, Bosnia-Herzegovina. My session was about how to begin developing…
I just attended the 2nd Microsoft NetWork event in Bosnia-Herzegovina. I spoke about how to start with SharePoint development for existing…
I attended the Windows 8 Tour and Camp, held in the beautiful city of Seville (Spain) on March 22nd and 23rd. The presenters, Boris Armenta…
We live in a evolving and changing world. For us developers, the times they are a-changin’ at an ever-increasing pace. We have new versions…
Aprovecho para subir la presentación de PowerPoint que utilicé para dar el seminario de pasiona consulting llamado “SharePoint: Presente y…
Ya empiezan a aparecer los primeros rumores sobre SharePoint vNext (SharePoint 15) en Internet. Por supuesto, todo lo que sigue son…
El compañero David Martos ha subido el material de las dos charlas que dimos el pasado jueves día 3 de noviembre. Podéis acceder al…
El último día de la Conferencia europea de SharePoint fue muy interesante, haciendo de un colofón muy digno al evento. Building User Forms…
Estoy orgulloso de poder anunciar el segundo evento presencial del SharePoint User Group de Catalunya (SUG.CAT). Microsoft ha tenido la…
Continuando con la conferencia de SharePoint en Berlín, hoy ha sido un día muy interesante. La keynote (presentación inicial) ha sido muy…
Hoy he asistido al primer día de la conferencia europea de SharePoint en Berlín. Para mí ha sido un día especial porque he hecho mi primera…
Entre los días 17 y 20 de octubre de 2011 la capital alemana se convertirá en la capital europea de SharePoint. Se celebrará la Conferencia…
El jueves pasado, día 17 de marzo de 2011, se realizó el primer acto presencial del grupo de usuarios de SharePoint de Catalunya (SUG.CAT) e…
Es un placer invitarles al primer evento presencial de la comunidad de usuarios de SharePoint de Catalunya (SUG.CAT), que hablará sobre…
Yesterday I was challenged with a task that seemed trivial but it was a real pain to solve. The customer had a VB.NET application that…
Hello again to all the readers of my blog. I haven’t been around lately, but I have a good excuse for that: I was getting married. Now, as…
A really weird situation happened yesterday at work. The Symptoms We wanted to move the Virtual Machine that serves as a SQL Server for our…
As you can probably remember, my frequency of blog posts here has been reduced in the last months. The reason is simple: I’ve been engaged…
I’ve been pulling my (scarce) hair when suddenly the Developer Tools in IE8 didn’t appear as expected, on one day. The taskbar in Windows…
Mi ex-compañero Eduard Tomàs ha escrito un artículo en su blog que me ha gustado mucho por la magnífica exposición que hace de un tema tan “…
El el primer post sobre la comunidad de SharePoint en español hice un repaso de los grupos y páginas “oficiales” de SharePoint. En esta…
I have a shiny new Windows 7 Ultimate 64-bit edition installed on my Dell laptop but in the last month I’ve been suffering intermittent BSOD…
Hace unos años era una aventura fútil encontrar información decente sobre SharePoint en español. Salvo, claro está, de los maestros Gustavo…
http://spg.codeplex.com/ A new drop of the official SharePoint Guidance. It now covers SharePoint 2010 and further expands on the SharePoint…
La próxima vez que alguien os pregunta “pero, ¿qué es SharePoint?”, le podéis enviar una copia de este documento. He intentado hacer un resu…
Siguiendo con la conversación muy interesante en el grupo HispaPoint de LinkedIn, he recopilado una lista de blogs de SharePoint en español.…
Recently, together with my colleague Martin Schmidt, I gave a session on MOSS 2007 to SharePoint 2010 migration. Among other things I…
Por fin me he decidido a hacer un blog en español sobre mi experiencia con SharePoint. Varias razones me han llevado a ello, entre otras la…
I’ve decided to write a new blog, in parallel with this one, with the Spanish-speaking SharePoint audience in mind. As I work in Barcelona (…
I wrote a short article in Spanish .NET magazine called DotNetManía about the SharePoint Conference 2009 in Las Vegas. I’ve just found out…
Microsoft has announced that pre-configured machines with Office 2010 Beta and SharePoint 2010 Beta 2 are now available for download. There…
The good people at Visual Studio Rangers have provided quick reference cards for many VS2010 features. Their aim is to use them as a quick 5…
Certification Path for Developers 70-573 TS: Microsoft SharePoint 2010, Application Development Microsoft Official Curriculum: Five-day…
More than a year ago, I wrote a summary post about the rumours and buzz around the next version of SharePoint (SP2010). My post has seen a…
I’ve been able to set up a Hyper-V Server 2008 R2 in a spare server box at work. I wanted to set up remote management from my Windows 7, als…
I run it on a VMWare Workstation 6.5 inside Windows 7 32-bits. The virtual machine is 64-bits, of course. My first impression is that SP2010…
For the MSDN Subscribers only, for the moment.
This session was dear to my heart, as the end-user adoption is really a tough thing to achieve. The session was presented by Scott Jamison…
This was my last session at the SharePoint Conference 2009 in Las Vegas. Tomorrow I fly back to the real world :-( At least, I splashed up a…
On Microsoft TechNet: http://download.microsoft.com/download/8/C/6/8C65AC6A-C09A-4E47-B2AD-0719EAA062F9/EvaluateSharePointServer2010-IT…
On this second day of SharePoint Conference in Las Vegas, I attended two sessions that were specific on document management improvements in…
Today the HUGE information stream began flowing, starting with a keynote by Microsoft CEO Steve Ballmer and SharePoint directors Jeff Teper…
This session was delivered by Paul Andrews, Microsoft Technical Product Manager for SharePoint. It was really “techie” stuff, but summarized…
This afternoon, the sessions I attended were about SharePoint Administration improvements. The sessions (Part 1 and Part 2) were delivered…
I arrived yesterday evening to Las Vegas. Today I did the registration process and I strolled The Las Vegas Strip (officially called Las…
Yes, I’ll be attending the SharePoint Conference 2009 (SPC09) next week in Las Vegas, Nevada. I will leave this Saturday for Las Vegas (via…
I’ve made a custom SPExport and SPImport tool that duplicates site content around the SharePoint site collection. However, it would suddenly…
SYMPTOMS The Event Log shows the following error entry for Office Server Shared Services with Event ID 6482, every couple of minutes: Appli…
I’ve just stumbled across this free SharePoint IT Pro / Dev training by Microsoft. It’s currently open to nominations. Only the partners…
OK, I admit that the title is a lame pun to the Happy Tree Friends cartoon series. In this installment of the Road to SharePoint 2010 I want…
Today I want to comment on what should you take care of when preparing your SharePoint 2007 customizations for the 2010 world. The Good Guys…
A weird thing happened to me yesterday when I was trying to edit a couple of work items in Team Foundation client from Visual Studio 2008.…
Welcome to the second installment of the Road to SharePoint 2010 series. I will tackle the oldest news for this SharePoint version: it will…
I’ve decided to start a new series of articles, called Road to SharePoint 2010. What I’m trying to achieve is to summarize what a SharePoint…
After so much silence, a wealth of SharePoint 2010 information has been disclosed from Microsoft. They’ve put together a site with videos…
Interesting behaviour that I saw yesterday. I had a MOSS 2007 site with a custom permission level defined on it. The users that had this…
The WSS 3.0 June 2009 Cumulative Update über-package and MOSS 2007 June 2009 Cumulative Update individual packages are ready for download. M…
I’ve been resuming my collaboration on MSDN SharePoint forums lately, so that’s why I’ve been slow to update the blog these days. I answer…
They are based on the Tech-Ed Visual Studio demonstration video. In one moment the presenter opens a SharePoint portal but it’s 2010 pre…
Today I had a strange error happening trying to deploy a WSP package on a SharePoint farm that had 2 front-end servers. On my local…
Welcome to a new post of “My Adventures in SIlverlight” series. In this post I’ll try to outline a few caveats I found while trying to…
Yes, that’s right! What a Dutch painter has to do with a Microsoft server solution? Well, the answer is not an obvious one: The FrontPage (…
(Thanks to my work colleague Cesar for pointing out this case to me) SYMPTOMS You have a custom list event receiver in SharePoint. You trap…
I’ve just stumbled upon this extraordinary offer. I’ve been evaluation Typemock before and it’s one of the best (if not the best) unit…
Today I’ve been greeted by a half-broken SharePoint 2007 development machine. It’s a small farm with one MOSS 2007 server and a SQL Server…
I’ve been trying to upgrade my development virtual machine to SharePoint 2007 SP2 today. No problems, except for the tiny detail…. The…
At the end, the ugly duckling of Microsoft Office suite is joining the SharePoint family. Microsoft announced that the Groove file…
Finally, the official words from Microsoft: the new incarnation of SharePoint server product will be named “Microsoft SharePoint Server 2010…
Microsoft released few months ago a business-oriented guide that explains how businesses can actually save money in these times of crisis…
In a recent project, I had to find out which of the workflows in the site collection were made with SharePoint Designer. I did a recursive…
A surprise from Microsoft! They’ve decided to offer SharePoint Designer 2007 free of charge from April 2nd. I think it will give an extra…
This time the guys at the Microsoft Support have leaked some juicy details about the next version of SharePoint. In their description of the…
Another of the strange, unexplained errors with a simple (yet unexpected) cause. SYMPTOMS You are developing an ASP.NET Site or Web Project…
Another strange error happened to me on customer premises. THE SYMPTOMS You have developed a custom discussion list in SharePoint. You have…
Even if it’s not officially announced, the new Cumulative Updates for SharePoint 2007 were released few days ago. WSS 3.0 Cumulative Update…
In this second installment of “My Adventures with Silverlight” series, I will talk of how to successfully invoke a WCF service from…
If you’ve been returning to my blog in the past month, you could see that I haven’t written anything since December the 3rd. I haven’t…
A really weird bug with SharePoint happened today. SYMPTOMS You have a standard MOSS 2007 Approval or Collect Feedback workflow configured…
At TechEd EMEA in Barcelona, the Visual Studio 2010 tools for SharePoint were announced and demonstrated. What was showed was the…
I’m still digesting the changes in .NET 3.5 and SP1, and the guys from Redmond already make a training kit for the next version of the…
Just a quick lesson learnt today in field: SCENARIO You want to use JavaScript to validate certain fields when the SharePoint page is in…
How many times you’ve seen the small SharePoint content database and a huge transaction log by its side? And the corresponding “Not enough…
It was about time that the old .net logo becomes .NET (the capitalized case is the correct name of the platform). The “wavy” new logo is…
I’m in the process of digesting the wealth of information that is pouring from PDC 2008 that’s in progress right now. I was unable to…
There are official news about SharePoint 2007 and WSS 3.0 Service Pack 2 (SP2) from Microsoft TechNet. The new service pack will contain: I…
Intermediate Level Books <table border="0" cellspacing="0" cellpadding="2" width="973"><tbody><tr><td valign="top" width="274">Title</td><td…
Microsoft Office SharePoint Server 2007 has moved from the “Visionary” quadrant into “Leaders” quadrant, in the past year. According to Gar…
Let’s do a quick recap about what we could expect from the next version of SharePoint from Microsoft: <table border="0" cellspacing="0…
Ok, I admit that the joke attempt wasn’t even remotely funny ;-) Being in SharePoint business for several years now has exposed me to lot of…
Yesterday a misleading error happened. A custom layout was deployed using Features and WSP solution packages. Everything went well, but when…
Glancing over the new entries at MSDN for SharePoint, I noticed an article by the name of “Capitalizing On the Social Network Capabilities…
A couple of weeks ago, Microsoft, EMC and IBM announced that they agreed on a joint specification of interoperability between their content…
An annoying “design bug” that happened to me today. SPListItem item = …(get a valid SPListItem)… SPField fieldDef = item.Fields…
Acting on the feedback I received, I fixed some bugs in my User Profile related Activities for SharePoint Designer. I changed the version…
As you might know, Microsoft has released a service pack for .NET Framework 3.5 few days ago. Let’s see what it adds to the standard…
Although I’m much more involved with CKS:IEE and CKS:CIE editions of Community Kit for SharePoint (CKS), I’ve been playing lately with CKS…
Finally, an independent association for all of us SharePointers is born. ISPA (International SharePoint Professionals Association) has…
(a new buzzword to learn, together with “hotfix”, “patch”, “service pack” and “update”.) Well, the thing is that the good folks at Microsoft…
Yesterday SharePoint greeted me with this error message when I tried to create a new site inside a site collection: File not found. I…
I just completed a Proof-of-Concept setup to allow the users to remotely access files that sit on a network share, using SharePoint and IIS…
As you might know, I contribute to Community Kit for SharePoint (CKS). It’s a CodePlex-hosted community project aimed to provide the…
Master Data Management: It seems that Microsoft last year acquisition of Stratature will result in their MDM mechanism being a part of…
(In addition to my previous blog entry speculating about the features of the next version of SharePoint) the SharePoint 2009 will be availa…
It’s really annoying that SharePoint displays those pesky column names followed by a colon when you group by a column. In this example I use…
Tired of changing the font size when teaching Visual Studio? Try this new miracle tool from Mark Russinovich and SysInternals Team (now on…
Another one of those “oh my god” moments in SharePoint programming, although it had nothing to do with SharePoint proper. The Background I…
Excellent news! The SharePoint team has released the Visual Studio Extensions for Windows SharePoint Services (VSeWSS) version 1.2. The only…
If you are comfortable in .NET development but SharePoint has always been a murky water for you, check out the new MSDN content tailored…
Following on the weird Windows XP network errors, such as the mysterious connecting to 1.0.0.0 site, I experienced another unexplained…
The good folks from Bamboo Solutions (these guys make tons of webparts, check them out) have made a setup bootstrapper called WssVista for W…
UPDATED 04/07/2012: I had issues with SkyDrive and lost the files but the WSP file has been retrieved by one of the previous downloaders…
I often try things on my SharePoint virtual machine that I keep on my laptop, hosted in VMWare Server environment. A few months ago suddenly…
I'm disappointed about how my stylish Sony VAIO built-in speakers sound so weak compared to my older HP laptop equipped with sleek Altec…
Microsoft announced on May 21st that the new Service Pack for Office 2007 (SP2) will add native support for ODF and PDF files. Yes, that…
A really weird error happened on one of my older computers, running Windows XP SP2. I successfully established a Wireless connection with an…
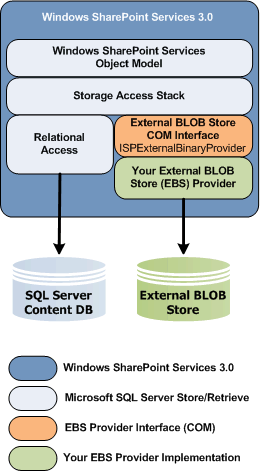
Few months ago I noticed that the WSS 3.0 introduced the notion of a external file storage provider to SharePoint world. Since then I kept…
I came across this annoyance on my boss' computer today. He had no "Hibernate" option on shutdown in his Vista Business laptop. Luckily, the…
Few days ago I did the last remaining SharePoint exams, which I was postponing for a long time due to everyday tight agenda. Now I join the…
For two times in a row this week I was asked to do a buddy check of .NET code that performs databinding. I found out that the order of the…
The good folks at CMS Watch wrote their "crystal ball" predictions in CMS world last December. There is one prediction regarding SharePoint…
Wow, that's fast! I'm still digesting the NET Framework 3.0 training (mainly over WPF now) and the folks from Redmond deliver their first…
If you were not aware, Microsoft released a bunch of PDF documents specifying various protocols that SharePoint uses to communicate…
Some of the main Microsoft Office SharePoint Server 2007 competitors (according to Gartner Magic Quadrant for ECM) can be found in this…
There's no official information by Microsoft about the next version of WSS 3.0 / MOSS 2007 technologies. Nevertheless, there are bits of…
I'm a big fan of NetStumbler WiFi discovery tool, but I'm sadly disappointed that it's not supported under Microsoft Vista. However, we can…
More often than not, I see how newbie .NET programmers are confused when trying to trace ASP.NET applications. The origin of the confusion…
I've been asked many times how to add a confirmation dialog for a simple (or complex, why not?) ASP.NET web form. It's simple: Find the OnC…
In ASP.NET you can remove an item from the web cache by invoking Cache.Remove(string ID). But, what happens when, for some reason, you want…
I'm much fond of the Flo's excellent Notepad2 editor. Replacing the simple built-in Notepad is one of the first things that I customize on…
Funny thing happened today when I tried to export / import a site from one site collection into another one. It asked me to close the Summar…
Sometimes we want SharePoint to import only the user profiles of those user that belong to one specific Active Directory group. In this case…
If you try to customize the "I Need To..." web part, as outlined by Gary in his blog post, you might experience a JavaScript error, just…
I downloaded the Beta 1 of Internet Explorer 8 from http://www.microsoft.com/windows/products/winfamily/ie/ie8/default.mspx and I was…
This nasty error is shown in Event Viewer when Office SharePoint Search crawler process can't process "My Sites" to index the users. The…
Finally, the long-awaited SP1 for WSS 3.0 / MOSS 2007 have been released. You can find them at Microsoft Downloads page: WSS 3.0 SP1 MOSS…
(via Mart Muller) It seems that the SP1 for MOSS 2007 is just a week away, scheduled for December the 12th! Wondering what it contains…
How many times you had to set up a SMTP service just to test that your .NET application sends the e-mail correctly? I found that I can test…
The last in the list of SharePoint quirks happened to me few days ago. The Symptoms You have a SharePoint Designer workflow that has a Pause…
I was looking for a way to quickly upload some documents into a SharePoint document library, when I stumbled upon this fine helper class by…
Excel Services cannot render a workbook that contains external data ranges displayed as a table, as mentioned in the documentation. I had to…
Well, it's been few months ago since I joined Community Kit for SharePoint (CKS) project on CodePlex. To me it seems like yesterday... Final…
Another undocumented piece of SharePoint. I want to validate two fields on a new list item form by invoking JavaScript custom function. They…
One of the main drawbacks of SharePoint Designer-based workflows is that you cannot reuse an existing workflow in another list. Recently, I…
After the (deserved) summer vacation period, I resumed the "normal" work schedule. One of the first issues I had to solve was how to display…
I tried to install a new beta of Windows Live Writer (WLInstaller.exe) on my Vista x64 and I met the spartan error message: Windows Live…
I was surprised to see that after a major Windows update process (the August 14th one) my VMWare Server stopped working. It began to give…
I've been trying for a week to make a workflow activity that would parse all user profiles and find a user with a specific title. At first…
Updated (18/03/2008): There's an extended custom web part made by Paul that does the same thing and much more. You can start reading from he…
SPFieldUser field type stores the username in "1#;User" fashion. This is a small annoyance when trying to access the user data, for instance…
This one was *really* weird stuff. - There is a SPD-created workflow that creates successive approval tasks, using Collect Data From a User…
As I recently reinstalled Vista (as I explained in my previous post), all the drivers for my Vaio laptop had to be reinstalled too. It all…
I've been trying to activate my corporate Vista Enterprise license, as I reinstalled Vista in 64 bits mode. I tried to activate online and I…
Today I was setting up a fresh virtual machine with MOSS 2007 and I met the dreaded "An unknown error has ocurred" message after the…
I crafted a handful of custom workflow actions for SharePoint Designer recently and I noticed several recurrent errors: When you select a…
If you use the built-in activity of SharePoint Designer workflow "Send email", you can embed the URL of the current item ("Absolute Encoded…
Exciting news! The CKS 2.0 has been pre-released. It's just been a few months since the project started and we already have something…
Today I've been working on a "Early Warning" workflow designed with SharePoint Designer. It is supposed to run on every item change and to…
Few months ago I joined Community Kit for SharePoint team. It's a collaborative open-source effort to extend and adapt SharePoint for…
I'm annoyed by many little details of the SharePoint Designer Workflow editor, but the main one is that it profligates in the creation of…
Microsoft released, at least, a quick-and-dirty hotfix that fixes up several issues with SharePoint Services 3.0. In particular, I've found…
I found this "descriptive" error message in a fragment of MOSS 2007 code in a webpart that uploads and tags a document with appropriate…
The most convenient way is to pass the user credentials from the client to the web service, providing a DefaultCredential object to the…
In a fragment of a code I'm working on, I must serialize a collection of links into an XML file. Fortunately, .NET Framework provides a…
If you are used to the ASP.NET Cache object, you can use it in SharePoint (after all, it's just an ASP.NET extended application). However…
Seeing many of those “descriptive” SharePoint errors like this one lately: Error The "MyWebPart" Web Part appears to be causing a problem.…
In a project I’m working on, I have to authenticate a user on a custom SharePoint 2003 login form (Yes, that’s possible….more on it will be…
I've been looking for information about the new buzzword in town: Ruby on Rails (aka RoR). I thought it was just another web development…
Hello, This entry is written from Word 2007 Beta. This feature is really astounding and time-saving. Step-by-step Guide: Open Word 2007 Cho…
Hello there! My first technical blog finally comes to the daylight. Isn't it a thrilling experience? I expect this blog to steadily grow…















































































































































































































































































